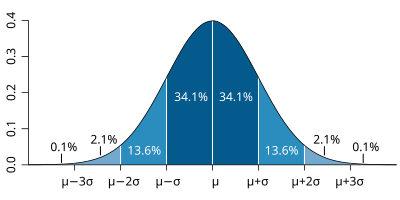
System Global Area (SGA)
En ella, se mantiene el diccionario de datos y las áreas compartidas
de las órdenes SQL que se solicitan para su procesamiento.
Database Buffer Cache:
Es el cache que almacena los bloques de datos leídos de los segmentos
de datos de la BD, tales como tablas, índices y clusters. Los bloques modificados se llaman
bloques sucios. El tamaño de buffer cache se fija por el parámetro DB_BLOCK_BUFFERS del
archivo init.ora. Tener en cuenta que la información leída desde disco, es leída por bloques no
por registros; esto se debe a que la estructura de almacenamiento más pequeña de la base de
datos, es un bloque. Los bloques son mantenidos en el database buffer cache de acuerdo al
algoritmos de Least Recently Used (LRU).
Buffer Redo Log:
Los registros Redo, describen los cambios realizados en la BD y son escritos en los
archivos redo log para que puedan ser utilizados en las operaciones de recuperación hacia adelante,
roll-forward, durante las recuperaciones de la BD. Pero antes de ser escritos en los archivos redo log,
son escritos en un cache de la SGA llamado redo log buffer. El servidor escribe periódicamente los
registros redo log en los archivos redo log. El tamaño del buffer redo log se fija por el parámetro
LOG_BUFFER.
Shared SQL Pool:
En esta zona, se encuentran las sentencias SQL que han sido analizadas. El análisis
sintáctico de las sentencias SQL lleva su tiempo, y Oracle® mantiene las estructuras asociadas a cada
sentencia SQL analizada durante un tiempo para verificar si puede reutilizar las sentencias previas.
Antes de analizar una sentencia SQL, Oracle® verifica en el Shared Pool por otra sentencia
exactamente igual en la zona de SQL compartido. Si es así, no la analiza y pasa directamente a
ejecutar la que mantiene en memoria. De esta manera se premia la uniformidad en la programación
de las aplicaciones. La igualdad se entiende que es lexicográfica, espacios en blanco y variables
incluidas.
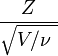
 es una variable aleatoria que sigue la distribución t de Student no central con parámetro de no-centralidad
es una variable aleatoria que sigue la distribución t de Student no central con parámetro de no-centralidad  .
.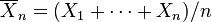




 es igual a n − 1.
es igual a n − 1. , lo cual es muy importante en la práctica.
, lo cual es muy importante en la práctica.
 para x>0
para x>0